AI Agent ที่ฉลาดขึ้น อาจอันตรายขึ้นด้วย ถ้าเราไม่มีระบบคุมมั…
AI Agent ที่ฉลาดขึ้น อาจอันตรายขึ้นด้วย ถ้าเราไม่มีระบบคุมมัน”
🧠 ทำยังไงให้ AI Agent “ฉลาดขึ้น” โดยไม่ทำให้มัน “อันตรายขึ้น”?
ช่วงนี้หลายคนเริ่มเล่น AI Agent กันหนักขึ้น
ไม่ว่าจะเป็น Hermes Agent, OpenClaw, Claude Code, Codex, Cursor, Gemini CLI หรือ Agent Framework อื่น ๆ
แต่คำถามสำคัญไม่ใช่แค่ว่า
“ใช้โมเดลอะไรดี?”
คำถามที่ใหญ่กว่านั้นคือ
เราจะทำให้ Agent ทำงานเก่งขึ้น ปลอดภัยขึ้น และไว้ใจได้มากขึ้นได้ยังไง
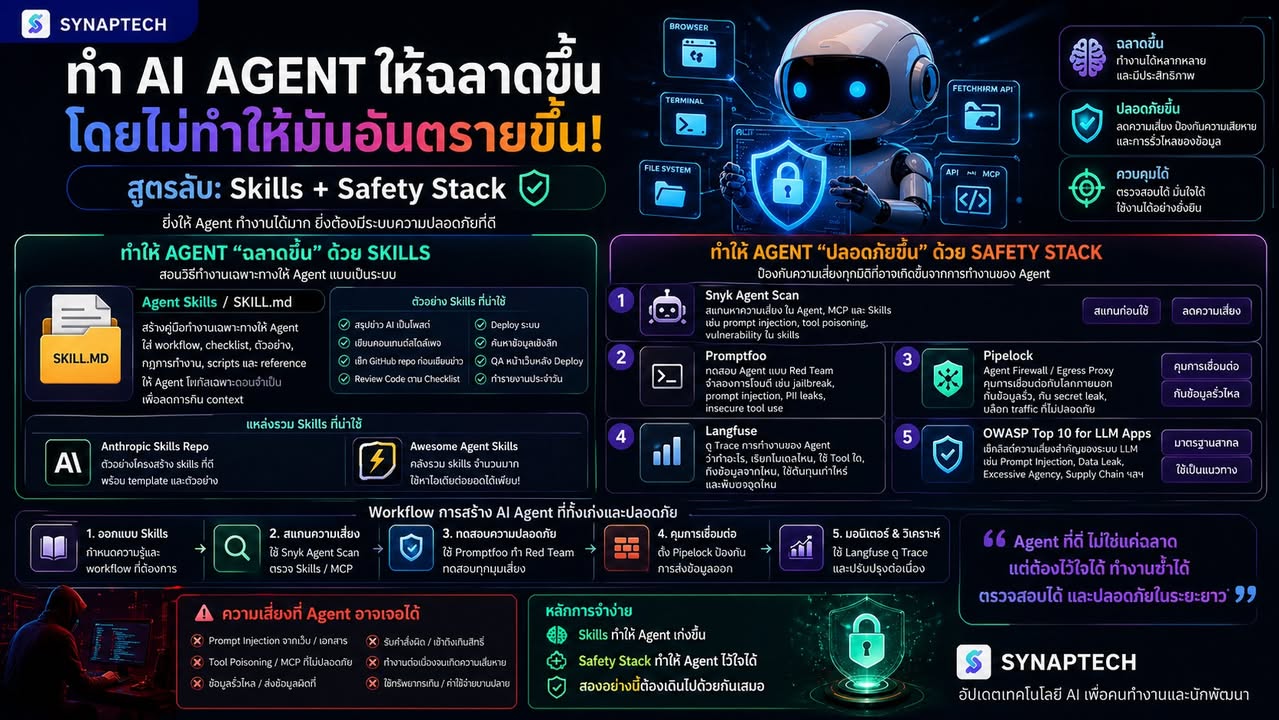
คำตอบหนึ่งที่น่าสนใจมากคือ Agent Skills
Skills คือการสอนความรู้เฉพาะทางให้ Agent แบบเป็นระบบ
แทนที่จะพิมพ์ prompt ยาว ๆ ซ้ำทุกครั้งว่า ต้องทำงานยังไง ต้องเช็กอะไร ต้องใช้ format แบบไหน ต้อง deploy ยังไง ต้องเขียนโพสต์สไตล์ไหน ต้อง review code ตาม checklist อะไร
เราสามารถทำเป็น Skill เก็บไว้เลย
พอ Agent เจองานที่เกี่ยวข้อง มันค่อยโหลด skill นั้นขึ้นมาใช้
พูดง่าย ๆ:
Skills = คู่มือทำงานเฉพาะทางของ AI Agent
เช่น
• Skill สำหรับสรุปข่าว AI เป็นโพสต์ Facebook • Skill สำหรับเขียนคอนเทนต์สไตล์เพจ • Skill สำหรับเช็ก GitHub repo ก่อนเอามาเขียนข่าว • Skill สำหรับ deploy เว็บ • Skill สำหรับ review code • Skill สำหรับเช็ก security ก่อน merge • Skill สำหรับทำรายงานประจำวัน • Skill สำหรับ QA หน้าเว็บหลัง deploy
นี่คือจุดที่ Agent เริ่มฉลาดขึ้นแบบใช้งานจริง
เพราะมันไม่ได้อาศัยแค่ความจำของโมเดล แต่มันมี workflow, checklist, reference และ script ที่เรากำหนดเอง
แต่ปัญหาคือ:
ยิ่ง Agent ฉลาดขึ้น ยิ่งให้มันใช้ tool ได้มากขึ้น ยิ่งให้มันเข้าถึงไฟล์, terminal, browser, API, server หรือ MCP ได้มากขึ้น
ความเสี่ยงก็ยิ่งเพิ่มขึ้นเหมือนกัน
เพราะ Agent ที่มีสิทธิ์เยอะเกินไป อาจพลาดได้ เช่น
• อ่านไฟล์ที่ไม่ควรอ่าน • ส่งข้อมูลออกไปผิดที่ • รันคำสั่งผิด • โดน prompt injection จากเว็บหรือเอกสาร • ใช้ tool ปลอม / tool poisoning • ทำ action เกินขอบเขต • ใช้ token หรือ resource จนบานปลาย • ทำงานต่อเนื่องโดยไม่มีคนตรวจ
เพราะงั้นยุคต่อไปของ AI Agent ไม่ควรมีแค่ “Skills”
แต่ควรมีสิ่งที่เรียกว่า
Agent Safety Stack
หรือชุดเครื่องมือคุมความปลอดภัยของ Agent
แนวคิดง่าย ๆ คือ:
Skills ทำให้ Agent เก่งขึ้น Scanner ทำให้เรารู้ว่า Skill หรือ MCP เสี่ยงไหม Guardrails ช่วยกันคำสั่งอันตราย Firewall คุมว่า Agent ส่งข้อมูลออกไปไหนได้บ้าง Observability ช่วยดูว่า Agent ทำอะไรไปแล้วบ้าง
ตัวอย่างเครื่องมือที่น่าจับตา:
Snyk Agent Scan ใช้สแกน agent, MCP server และ skills เพื่อหาความเสี่ยง เช่น prompt injection, tool poisoning และ skill ที่อาจอันตราย
Promptfoo ใช้ทดสอบ Agent แบบ red team จำลองการโจมตี เช่น jailbreak, prompt injection, PII leak หรือ insecure tool use
Pipelock แนว Agent Firewall เอาไว้คุม traffic ระหว่าง Agent กับโลกภายนอก ลดความเสี่ยงเรื่อง secret leak และการส่งข้อมูลออกผิดทาง
Langfuse ใช้ดู trace ของ Agent ว่าระหว่างทำงานมันเรียก model อะไร ใช้ tool ไหน ดึงข้อมูลจากไหน และพังตรงจุดใด
OWASP Top 10 for LLM Apps ใช้เป็น checklist ความเสี่ยงพื้นฐานสำหรับระบบ LLM / Agent เช่น prompt injection, data leak, supply chain และ excessive agency
นี่คือมุมที่ผมว่าน่าสนใจกว่าแค่ “Agent ตัวไหนเก่งกว่า”
เพราะในโลกจริง Agent ที่ดีไม่ได้วัดแค่ว่ามันตอบฉลาดแค่ไหน
แต่วัดว่า:
• ทำงานซ้ำได้ไหม • ใช้ workflow เดิมได้ไหม • ตรวจสอบย้อนหลังได้ไหม • จำกัดสิทธิ์ได้ไหม • กันข้อมูลรั่วได้ไหม • เจอ prompt injection แล้วไม่หลุดไหม • ใช้ tool อย่างปลอดภัยไหม • และถ้าพลาด เรารู้ไหมว่ามันพลาดตรงไหน
สรุปง่าย ๆ:
อนาคตของ AI Agent อาจไม่ได้ชนะกันที่โมเดลอย่างเดียว
แต่จะชนะกันที่ใครสร้างระบบได้ครบกว่า:
Model + Skills + Tools + Guardrails + Scanner + Logs
ถ้า Agent มีแต่ความฉลาด แต่ไม่มีความปลอดภัย มันอาจกลายเป็นความเสี่ยง
แต่ถ้า Agent มี Skills ที่ดี และมีระบบคุมความปลอดภัยรอบตัว
มันจะเริ่มกลายเป็น “ผู้ช่วยดิจิทัล” ที่ทำงานจริงได้มากขึ้น และไว้ใจได้มากขึ้น
นี่แหละคือสนามต่อไปของ AI Agent ครับ
#AIAgent #AgentSkills #HermesAgent #OpenClaw #MCP #AgentSkills #HermesAgent #OpenClaw #MCP #AIAgent #AgentSkills #HermesAgent #OpenClaw #MCP #AISafety #PromptInjection #DeveloperTools #AIWorkflow
📖 อ่านบทความเต็มบน Facebook | 🔔 ติดตาม SynapTech
รับข่าว AI และบทความใหม่ก่อนผู้อื่น ส่งตรงถึง inbox
บทความแนะนำ
ถ้าชอบเนื้อหาแบบนี้
กดติดตาม SynapTech บน Facebook