🚨 Server ล่มทีไร…ปัญหาไม่ใช่แค่ “ระบบพัง”
🚨 Server ล่มทีไร…ปัญหาไม่ใช่แค่ “ระบบพัง” แต่คือเราไม่รู้ว่า “มันเริ่มพังตรงไหน”
หลายทีมมี dashboard เต็มจอ มี log เต็มไปหมด มี alert เด้งทั้งวัน
แต่พอ incident จริงเกิดขึ้น… ยังต้องนั่งไล่เองว่า CPU ขึ้นเพราะอะไร, container ตัวไหนกิน resource, network เริ่มแปลกตอนไหน, หรือ deploy ล่าสุดไปกระทบอะไรไหม
นี่คือจุดที่ Netdata น่าสนใจมาก 👀
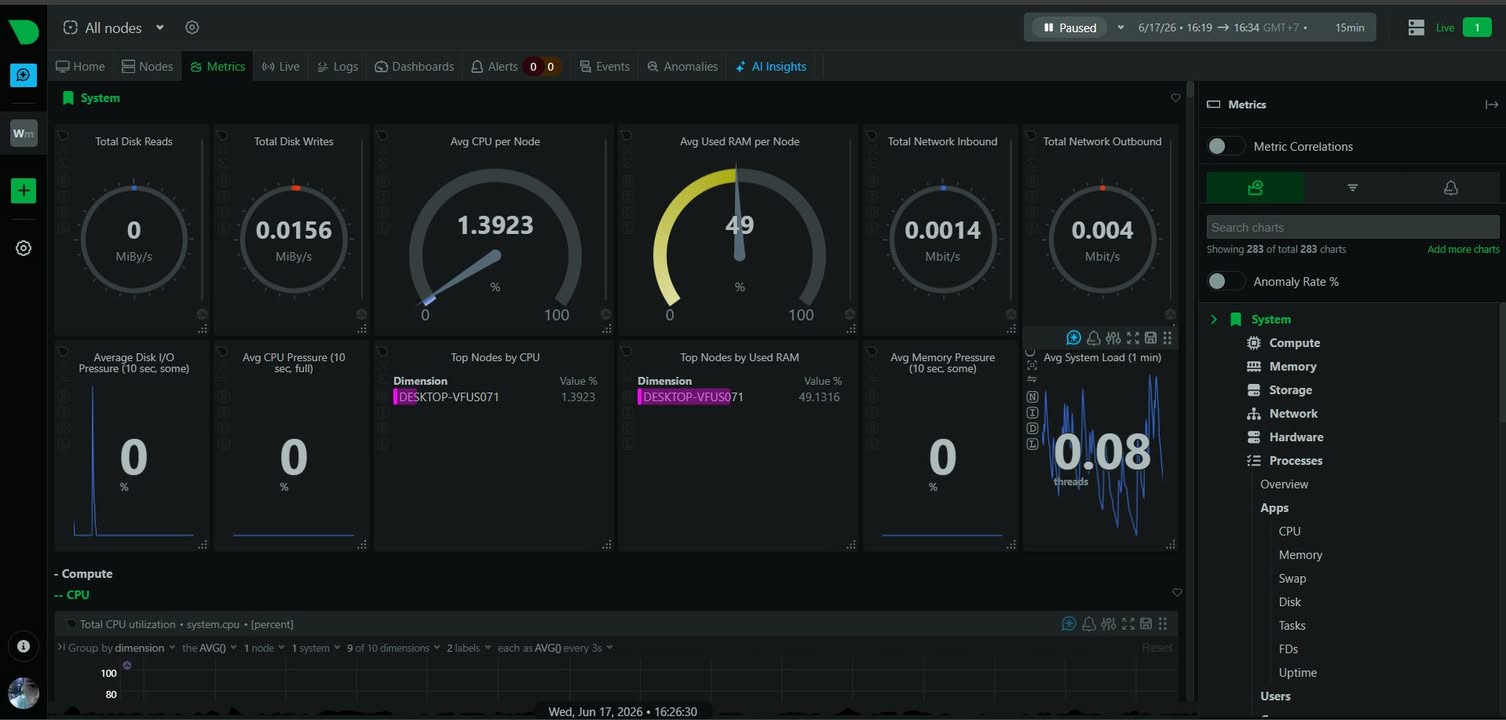
Netdata เป็น open-source monitoring / observability tool ที่ช่วยดูระบบแบบ real-time ระดับ per-second metrics พูดง่าย ๆ คือมันไม่ได้รอเฉลี่ยข้อมูลเป็นนาที ๆ แต่พยายามจับอาการเล็ก ๆ ที่เกิดขึ้นในระดับวินาที ซึ่งบางทีนี่แหละคือต้นเหตุของ incident จริง
ของที่ดูได้ก็มีทั้ง server, container, Kubernetes, app, network, logs, metrics และ infra หลายแบบในที่เดียว
จุดที่เข้ากับยุค AI มากขึ้นคือ Netdata ไม่ได้หยุดแค่ “โชว์กราฟ” แต่มันมี Netdata AI / AI Insights ที่ช่วยอธิบายว่าเกิดอะไรขึ้น ทำไมถึงเกิด และควรแก้ยังไงต่อ
Use case ที่เห็นภาพมาก ๆ เช่น DevOps ใช้ดู server/container แบบ real-time, ทีม infra ใช้จับ anomaly ก่อนระบบล่ม, ทีม AI/ML ใช้ monitor GPU cluster หรือ inference API, ส่วนทีมเล็กก็ใช้แทนการประกอบ stack monitoring หนัก ๆ ที่ต้องตั้งหลายตัว
พูดง่าย ๆ คือ Netdata ไม่ได้มาแทนสมอง engineer แต่มันช่วยลดเวลานั่งงม dashboard ตอนระบบมีปัญหา
จาก “กราฟเต็มจอแต่ไม่รู้เริ่มตรงไหน” กลายเป็น “เห็นอาการ เห็น timeline และมี clue ให้ไล่ต่อเร็วขึ้น”
สำหรับใครทำระบบ production, self-hosted, Docker, Kubernetes หรือ AI app ที่ต้อง monitor จริง ๆ ตัวนี้ควรอยู่ในลิสต์ที่ต้องลองครับ
เพราะในโลกจริง… ระบบไม่ได้พังตอนเราว่าง มันพังตอนลูกค้าใช้งานอยู่ 😅
ติดตาม SynapTech AI ไว้ครับ เดี๋ยวผมหยิบ tool / repo / workflow ที่เอาไปใช้ทำงานจริง มาเล่าให้เข้าใจง่ายเรื่อย ๆ
#SynapTechAI #DevOps #AIAgent #OpenSource #Monitoring
📖 อ่านบทความเต็มบน Facebook | 🔔 ติดตาม SynapTech
รับข่าว AI และบทความใหม่ก่อนผู้อื่น ส่งตรงถึง inbox
บทความแนะนำ
ถ้าชอบเนื้อหาแบบนี้
กดติดตาม SynapTech บน Facebook